What ZP does is up to ZP. If our Autocat system cannot find results in the last 30, 60 or 90 days for racing events only (not group rides) it will look even further back (which covers those that leave for the summer). It is also only the TEST events that do not allow you to select a higher class. While it isn’t a perfect system yet, we have been at this for many months and do keep up with the forums and feedback and are in daily contact with various devs - there wont be many things that have been missed and nothing has been mentioned so far that wasn’t in the original list of Zwifter gripes we are aiming to eradicate.
11 Likes
The Microsoft website is a little more informative than Wiki ![]()
1 Like
No, this autocat I’ve been given is a total lolz. I am fairly certain it’s going to be an absolute cakewalk for me. See for yourself
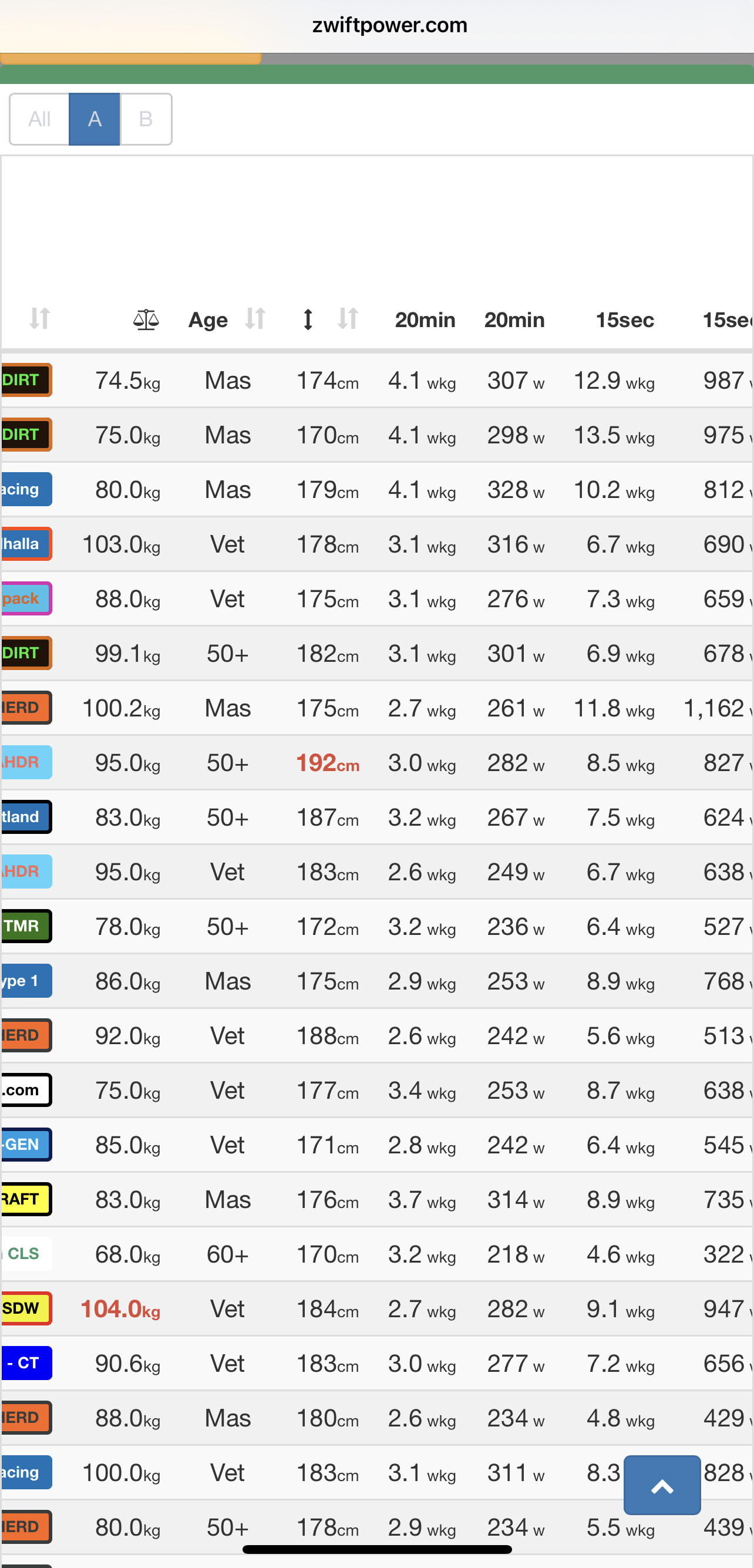
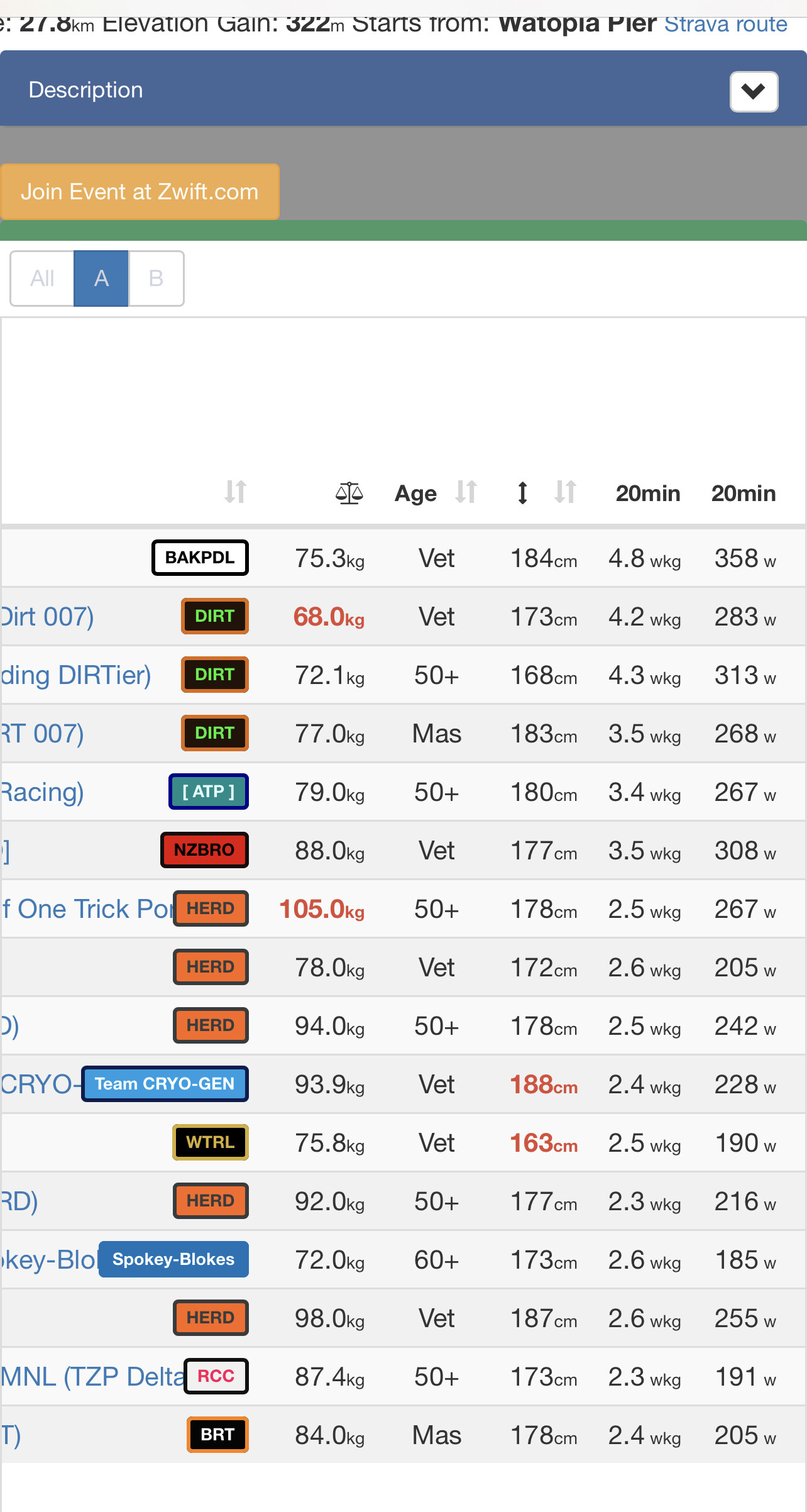
Anyone here seriously think my race spot is correct? I’m in cat 6 for the aussie timeslot
ZwiftPower - Login
Edit - I see there was a bug, check my post below
1 Like
I agree. There are obviously a lot of bugs in the system as currently implemented. My C3 race looks reasonable but there are some absolute ringers in the C5 and C6 races across the time zones, including people who regularly beat me in races.
1 Like
Ahhh I see now, there was a bug when I signed up. I’ll try again.
Well that’s more like it. C1 now.
1 Like
Looks like a good option, especially with the focus on ranking newer players (riders) as quickly as possible.
If you are actually looking beyond 90 days if needed, that’s great. You might want to consider revising the wording “Last 30, 60 and 90 days Racing Stats” on the Zwift Classics - WTRL page accordingly, though…
For these test events it doesn’t go beyond the 90 days as there is little to gain for either the race, the racer or the test itself so what the website says is correct for the test events.
I’m not sure if anything changed since these comments, but it looks to me as if the ‘flyers’ (obviously unintentional) are listed in two cats/events on ZP. One that appears reasonable and one that clearly isn’t. Not sure why and if this causes problems later on, but I suspect WTRL is aware and on it.
As a general comment: I’m very pleased to see this development and hope it works out well. It doesn’t need to be perfect from the start. I’m sure these test events will help evolve and fine tune the cat boundaries and highlight obstacles so that ultimately every cat and any course has good fair racing with (more importantly IMO) a natural progression from one cat to the next. I have full confidence that WTRL in collaboration with Zwift will develop this further. Great work.
1 Like
Yep, I have that issue. On the companion app I am in cat 1 pen. Zwiftpower sign ups shows me in cat6 and cat1.
I appreciate the work you have done on this. Having (effectively) a new set of cat boundaries will certainly freshen up the racing. However, I worry that conceptually it is still the wrong solution to the problem. Riders need to be promoted when they win/finish high, and demoted when they lose (or fail to have enough high finishes over a long period of time). It’s not a coincidence that basically every real-world performance-based categorisation system in every sport works like this, it’s because it is the only sensible thing to do. I know you talk about introducing some element of this in the future, and I hope it comes through quickly. Moving the cat boundaries just creates a different set of regular winners and regular losers. It’s a change but it’s not a solution.
1 Like
I still don’t get how grouping by speed on a course allows you to progress…
Speed is governed by the blob… you can’t go quicker or breakaway / therefore can’t over perform?
Would users not be continually in the same groups?
Large racers with multiple blobs will have a quicker overall time than sparsely populated races due to users having solo TT once dropped…
@Martin_WTRL might you be able to shed some light on this?
3 Likes
My understanding is that the system is based on a blending of performances and results. The latter creates a ranking of riders; the categories become containers for riders within a ranking range. Those who perform well improve their rankings and progress to ride against stronger riders, those who don’t see their rankings degrade (either relative to others, or in absolute terms when the system includes time-based reductions in points) and will ride against weaker riders.
Just the fact that you only have one option to choose and the WTRL/Zwift places you in the correct category for you is a big step in the right direction.
Great work, looking forward for testing it out tomorrow evening
5 Likes
This is just my interpretation of what I read with possibly some wishful thinking added from my side, but it appears to me that this system is useful to place riders with limited race history (return from off-season, occasional racer, etc). Question is if it’s an ‘or or’ classification, or ‘and, and’ classification. If the latter (which is my interpretation), then race time may give the initial seeding, the powercurve may be used to account for busy vs empty rides and to spot riders who are not racing close to their FTP or may otherwise be expected to be competitive in the next cat, while frequent winners or top finishers may be upgraded to the next cat based on results. Again, I’m just making this up, but it could provide a gradual transition until ultimately the emphasis for seeding is put more and more on the ranking system if it performs adequately.
Race grouping/grading doesn’t appear to be done dynamically… as it places you in the cat at sign up rather than at the point of joining the race… based on this it’s not grading you against opponent, but against all users…
So there should be a clear path to improve your grading which is currently unclear…
Basing it on speed, uses the speed of the blob and as you are graded on entry and not opponents you can effectively guess this to close proximity before the race.
You can probably predict to a close degree the average power for the race as you know the time (excluding the outliers)…
The concern is you race same types of races each race and you will struggle to improve as you need your opponents to also improve alongside you to make the blob go quicker…
Does the current game engine support grading by predicted time?
As an outsider, I would worry the blob effect hinders it to much…
Great work WTRL and Zwift field looks really good on the eye test and I’m familiar with many riders in my cat. Hope this continues to be prioritized by Zwift and that not only WTRL will have access to the function in the long run.
One thing I see can be a problem is that lighter cyclists end up in a too high ranking?
Maybe not to mention names but a former this strong B rider (now A), who is slightly better than me ends up in C1 instead of maybe more reasonable C2 / C3 (I am categorized as C3).
Hope you develop this further and take into account W’ and then can then can determine FTP from values other than 20 min power. Type that XERT and Golden Cheetah use after studies from e.g. Skiba, Olbrecht.
1 Like
It’s a change but it’s not a solution.
Spot on. We’re not calling this finished and the ultimate answer. This is just something to test over the summer as we look to something more robust.
9 Likes
I can’t make the test event this week (will be riding outside) but wanted to add my positive feedback for this idea and experiment. Fantastic stuff! ![]()
3 Likes